 I have been using Ivy for a couple of years now. Strangely, of all of the developers that I have introduced Ivy too, I think I’m the only one really jazzed by this approach. Some actually question the value of the tool; change is a hard thing! I think it is hard to see the real value of dependency management, especially when you only work on a single application, for an extended period of time. After all, once an application is wired up with the right libraries, what is the big deal? I tend to work on multiple projects and take a more board view of development issues. I seem to be the guy creates the Ant scripts, upgrades the libraries, and manage the dependencies between all of these tools; hence I’m a huge fan of dependency management! I see no better way to document the external dependency requirements of an application. From a corporate or even organization perspective, Ivy can provide additional value beyond development, it can support both compliance and configuration management activities. The value of a single, centrally managed, browsable repository of reusable components should not be overlooked. I believe that significant number of person-hours are lost each year on the simple task of component (open source and commercial) version management. Just think about the amount of time spent by a project to download new component versions (and their dependencies), update build scripts, manage them in a version control system, creating tags and branches for items that never change! Now, multiple that effort by the number of applications your company manages. I have to imagine this amount of time is more than insignificant. OK, my Ivy sermon is over; on to something that might actually be valuable.
I have been using Ivy for a couple of years now. Strangely, of all of the developers that I have introduced Ivy too, I think I’m the only one really jazzed by this approach. Some actually question the value of the tool; change is a hard thing! I think it is hard to see the real value of dependency management, especially when you only work on a single application, for an extended period of time. After all, once an application is wired up with the right libraries, what is the big deal? I tend to work on multiple projects and take a more board view of development issues. I seem to be the guy creates the Ant scripts, upgrades the libraries, and manage the dependencies between all of these tools; hence I’m a huge fan of dependency management! I see no better way to document the external dependency requirements of an application. From a corporate or even organization perspective, Ivy can provide additional value beyond development, it can support both compliance and configuration management activities. The value of a single, centrally managed, browsable repository of reusable components should not be overlooked. I believe that significant number of person-hours are lost each year on the simple task of component (open source and commercial) version management. Just think about the amount of time spent by a project to download new component versions (and their dependencies), update build scripts, manage them in a version control system, creating tags and branches for items that never change! Now, multiple that effort by the number of applications your company manages. I have to imagine this amount of time is more than insignificant. OK, my Ivy sermon is over; on to something that might actually be valuable.
Once you have your repository structured, Ivy works pretty well. Converting an Ant-based application to use Ivy is pretty trivial and always seems to work perfectly. On the other hand, the IvyDE plug-in has always been a little bit of pain, especially when you are working with a WTP project. After converting the first project to use Ivy, it was basically a cut and paste exercise for every other project. Unfortunately, there were a few side effects of using Ivy that I just finally got around to addressing. Not that these were huge issues, more a matter of cleanliness.
| Use multiple Ivy configuration files rather than one single file. |
We always use a single Ivy configuration file per project; it contains the dependencies for all activities: compiling, execution, jUnit, Clover, FindBugs, PMD, Checkstyle, etc. This made the Ivy configuration a little difficult to comprehend, as it was not 100% obvious which libraries were actually required to simply build the application. Additionally, this made the Ant build files and file system rather messy; we ended up with hundreds of jar files in the Ivy retrieve directory, not knowing if a tool or component was dependent on them. If the project happened to create a WAR file, we had to “hand pick” the files from the retrieve directory and provide a custom fileset of required files for the WEB-INF/lib directory. This was a continual maintenance issue, as someone would add a new dependency to Ivy and forget to update the custom path object in the Ant XML. To simplify and eliminate this problem, we decided to create two Ivy configuration files, one for the required components (ivy.xml), and one for the continuous integration / build environment (ivy.tools.xml). It was now much easier to visualize and manage the run-time components required to execute the application, independently from components needed to build and/or test the application.
| Use Ivy resolve Ant task rather than Ivy retrieve task, or better yet, use the Ivy cachepath task. |
The simplest Ivy strategy is to dump all the components into a single directory using the Ivy:retrieve Ant task. This approach gives direct access to the files and enables the creation of multiple filesets for specific uses. This is the easiest way to convert an existing project to Ivy, just re-point the build scripts to the new location. This approach aggravated some developers on the team, as we could end up with the same jar file in at least 3 different sub-directories on your machine; a copy in your Ivy cache, another copy in the Ivy retrieve directory, and another copy in the required location (WEB-INF/lib for example). The IvyDE plug-in uses files directly from the Ivy cache, no extra copies of the files are created. I should have picked up on this approach sooner, as it seems much more elegant. There are several post resolve tasks that can be used to implement this approach, namely the Ivy:cachepath task. This task creates Ant path objects with direct references to the file’s location within the Ivy cache. If you need a fileset object, you can utilize the Ivy:cachefileset task.
As you can see from the following example, it is easy to create multiple path objects from within your Ant build process. It is even possible to have extremely fine grain control, you can create path objects for individual modules, one for each specific tool if you so desired; I have not used this strategy yet, but it does seem interesting.
<ivy:settings file="ivysettings.xml" />
<ivy:cachepath pathid="classpath.CORE" conf="runtime" resolveId="CORE" file="ivy.xml" />
<ivy:cachepath pathid="classpath.CI" conf="runtime" resolveId="CI" file="ivy.tools.xml" />
<ivy:cachepath pathid="classpath.COMMON"organisation="beilers.com" module="common" revision="1.0" inline="true" conf="debug" />
Once you have your path objects created, you can use them just like normal in other tasks, nothing special here. It is that point that what makes Ivy so attractive from a build (Ant) perspective, in that Ivy does not require you to change the way you think or typically use Ant.
<javac source="1.5" destdir="${build.dir}" debug="${javac.debug.option}" verbose="no">
<compilerarg value="-Xlint:unchecked" />
<src path="src" />
<classpath>
<path refid="classpath.COMMON" />
<path refid="classpath.CORE" />
<path refid="classpath.CI" />
</classpath>
</javac>
I did run into one issue with the Ant <war> task using the Ivy:cachepath task. When the WAR file was created, the WEB-INF/lib directory did not get flattened. All of the dependent jar files were placed in sub-directories that mirrored the Ivy repository structure. Unfortunately, the <war> task <lib> section does not support the “flatten” option. (An Ant bug was actually filed in 2004 for this problem.) Luckily, the post gave me the appropriate Ant way of resolving the situation, using a new feature in Ant 1.8 called mapped resources. The XML seems a little convoluted looking, but works perfectly. I don’t think I would have ever figured this out without Google!
By combining all of these ideas into the Ant build build system, I can take advantage of the Ivy cache and eliminate all extraneous copies of jar files. The real value is provided by the multiple Ivy configuration files, making it completely unnecessary to know what jar files are included in each dependency. This approach makes the Ant build system significantly less error prone and eliminates all future maintenance concerning jar files.
<war destfile="${war.full.path}" webxml="WebContent/WEB-INF/web.xml" manifest="${manifest.path}">
<fileset dir="WebContent">
</fileset>
<classes dir="${build.dir}"/>
<mappedresources>
<restrict>
<path refid="classpath.CORE"/>
<type type="file"/>
</restrict>
<chainedmapper>
<flattenmapper/>
<globmapper from="*" to="WEB-INF/lib/*"/>
</chainedmapper>
</mappedresources>
<zipfileset dir="src" prefix="WEB-INF/classes">
<include name="**/resources/**/*.properties" />
<include name="**/resources/**/*.xml" />
</zipfileset>
</war>

 I have a love/hate relationship with the IvyDE plug-in when it comes to WTP project types. I have literally wasted hours of time trying to get IvyDE to publish into my web application. It is very strange, no pattern at all; it works fine for days at a time and then decides to stop working… I don’t believe that the team has actually developed a “reproducible pattern” of forcing WTP to publish the Ivy dependencies; it is a continual “trial and error” of the following steps, clean the project, Ivy resolve, clean Tomcat, un-deploy the application, redeploy the application; one of these will eventually cause WTP to push the dependencies over. Can you say, frustrating?
I have a love/hate relationship with the IvyDE plug-in when it comes to WTP project types. I have literally wasted hours of time trying to get IvyDE to publish into my web application. It is very strange, no pattern at all; it works fine for days at a time and then decides to stop working… I don’t believe that the team has actually developed a “reproducible pattern” of forcing WTP to publish the Ivy dependencies; it is a continual “trial and error” of the following steps, clean the project, Ivy resolve, clean Tomcat, un-deploy the application, redeploy the application; one of these will eventually cause WTP to push the dependencies over. Can you say, frustrating?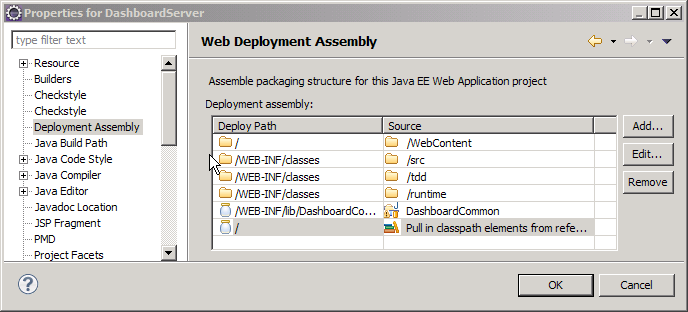
 This problem may have been answered in Eclipse 3.6 (Helios). I tested some of the 3.6 milestone releases, but was fooled into thinking that the IvyDE and WTP integration was broken; the J2EE module dependency option was no longer visible on the project properties. I was too busy to investigate (or look at other menu options!), I just assumed that it was just broken. To make a long story short, there is a new menu option called Deployment Assembly. The new option is a much simpler concept to comprehend; it is more flexible and actually seems to work consistently with Ivy. The most obvious change is the presentation; it gives a better picture of how the web application will be assembled. The old J2EE Module Dependency manager allowed you to choose components, but might have been more tailored for building an EAR file, rather than a WAR. Another issues is the inability to exclude any of the “source” folders. If you manage your unit test classes in a separate source folder, they would also be included in the application (WAR). Not necessarily a problem, but not very clean and could possibly hide unintended dependencies between the two source trees.
This problem may have been answered in Eclipse 3.6 (Helios). I tested some of the 3.6 milestone releases, but was fooled into thinking that the IvyDE and WTP integration was broken; the J2EE module dependency option was no longer visible on the project properties. I was too busy to investigate (or look at other menu options!), I just assumed that it was just broken. To make a long story short, there is a new menu option called Deployment Assembly. The new option is a much simpler concept to comprehend; it is more flexible and actually seems to work consistently with Ivy. The most obvious change is the presentation; it gives a better picture of how the web application will be assembled. The old J2EE Module Dependency manager allowed you to choose components, but might have been more tailored for building an EAR file, rather than a WAR. Another issues is the inability to exclude any of the “source” folders. If you manage your unit test classes in a separate source folder, they would also be included in the application (WAR). Not necessarily a problem, but not very clean and could possibly hide unintended dependencies between the two source trees.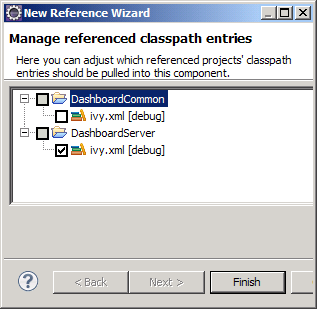 When using IvyDE, the first step is to add an Ivy classpath container. This will add Ivy dependencies to the classpath of your Eclipse project. If you have a WTP project, you will also need these dependencies copied to the WEB-INF/lib directory. This is easily accomplished by clicking the Add button under Deployment Assembly (under project properties). You can add other projects and external jars as well. Here is where it gets interesting, there appears to be two different options. If you have already added the Ivy classpath container to your build path, click the “Referenced Classpath Entries” option and select the ivy.xml file from your project. There might be a little display problem, as the “Deploy Path” for the classpath container does not appear correct, but it does put the libraries in the correct directory location.
When using IvyDE, the first step is to add an Ivy classpath container. This will add Ivy dependencies to the classpath of your Eclipse project. If you have a WTP project, you will also need these dependencies copied to the WEB-INF/lib directory. This is easily accomplished by clicking the Add button under Deployment Assembly (under project properties). You can add other projects and external jars as well. Here is where it gets interesting, there appears to be two different options. If you have already added the Ivy classpath container to your build path, click the “Referenced Classpath Entries” option and select the ivy.xml file from your project. There might be a little display problem, as the “Deploy Path” for the classpath container does not appear correct, but it does put the libraries in the correct directory location.








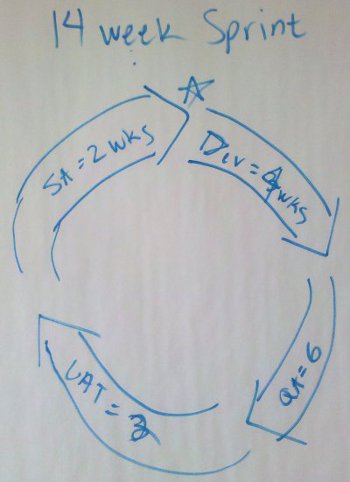 I might be dating myself, but when I was a kid, I remember my parents talking about
I might be dating myself, but when I was a kid, I remember my parents talking about 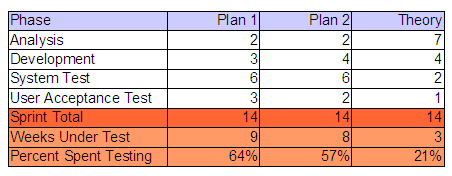 I threw together this little a table to illustrate my point. Based on either combination of values, the project was going to allocate between 57% and 64% of it’s project schedule to testing. Using the worst case numbers, we are talking about 3 times longer to test the code, than actually develop the code. Is it just me or is that crazy? What if you had two (2) months worth of development? Simple math, that would require six (6) additional months to validate! I realize there are or can be several factors contributing to this equation, but I’m pretty sure that we are not talking about a team of twelve (12) developers to one (1) tester, creating an unbalanced capacity situation. Just for fun, I threw a Theory column into my table. I can’t remember where I learned or read this, but I’m sure everyone knows this fact as well…
I threw together this little a table to illustrate my point. Based on either combination of values, the project was going to allocate between 57% and 64% of it’s project schedule to testing. Using the worst case numbers, we are talking about 3 times longer to test the code, than actually develop the code. Is it just me or is that crazy? What if you had two (2) months worth of development? Simple math, that would require six (6) additional months to validate! I realize there are or can be several factors contributing to this equation, but I’m pretty sure that we are not talking about a team of twelve (12) developers to one (1) tester, creating an unbalanced capacity situation. Just for fun, I threw a Theory column into my table. I can’t remember where I learned or read this, but I’m sure everyone knows this fact as well… 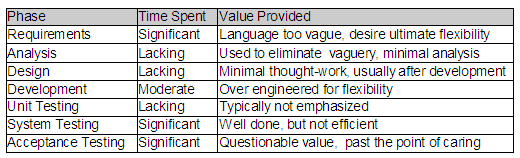 Unfortunately, we seem to be spending too much of our time in the wrong SDLC phase and on the wrong artifacts. I can’t tell you how many times I have seen a hundred (100) page requirements document for a seemingly trivial system. The SDLC mandates that these documents be produced, irregardless of the content’s quality. This is no fault of the business, they simply try to document their needs, given what they know. Because requirements are typically not allowed to evolve and are seldom interpreted correctly by the IT team, the business never gets what they really need. Additionally, the time spent by the testing teams to provide the traceability back to the excessively verbose requirements, while generating and documenting their test cases could almost be considered SDLC overhead. The testers are rarely given a chance to actually automate their test cases, which in my opinion, is the most valuable artifact of their job.
Unfortunately, we seem to be spending too much of our time in the wrong SDLC phase and on the wrong artifacts. I can’t tell you how many times I have seen a hundred (100) page requirements document for a seemingly trivial system. The SDLC mandates that these documents be produced, irregardless of the content’s quality. This is no fault of the business, they simply try to document their needs, given what they know. Because requirements are typically not allowed to evolve and are seldom interpreted correctly by the IT team, the business never gets what they really need. Additionally, the time spent by the testing teams to provide the traceability back to the excessively verbose requirements, while generating and documenting their test cases could almost be considered SDLC overhead. The testers are rarely given a chance to actually automate their test cases, which in my opinion, is the most valuable artifact of their job. I was reading the
I was reading the  I actually found two versions of the document by the author, Steve Pieczko. The
I actually found two versions of the document by the author, Steve Pieczko. The 

 Earlier this month, Kent tweeted about the “Pragmatic Magazine”. I had been to the “
Earlier this month, Kent tweeted about the “Pragmatic Magazine”. I had been to the “
 I assume that everyone performs some kind of unit testing… The real question is what does unit testing mean to you? For me, it is some form of repeatable, assertion-based approach that can be re-executed by other developers and a continuous integration process. Unit testing is just one piece in my software confidence puzzle. That sounds like a great topic for my next blog! Unfortunately, some developers think that generating some log messages to inspect or stepping through the code with a debugger accomplishes the very same thing. Depending on the competency of the developer, I believe this can be partially true; however what about the next developer who needs to change the code?
I assume that everyone performs some kind of unit testing… The real question is what does unit testing mean to you? For me, it is some form of repeatable, assertion-based approach that can be re-executed by other developers and a continuous integration process. Unit testing is just one piece in my software confidence puzzle. That sounds like a great topic for my next blog! Unfortunately, some developers think that generating some log messages to inspect or stepping through the code with a debugger accomplishes the very same thing. Depending on the competency of the developer, I believe this can be partially true; however what about the next developer who needs to change the code?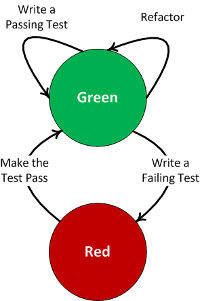
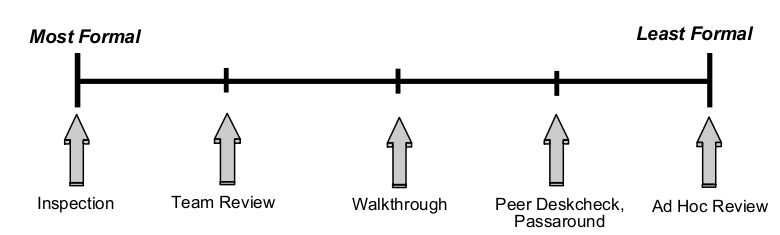 This first one really drives me crazy, but unfortunately, this appears to be the way that most teams perform their “code reviews”. First, the presenter/reader sets up a phone line for all of the participants to dial into, even if they all sit together in the same area! Next, the presenter sets up a “net meeting” and walks the team through the code; adding comments or making small fixes along the way. Maybe I have too limited of an attention span, but I don’t really commit to this type of code review, nor do many others from my observations. Inevitably, someone comes by with a question, or you get an interesting email or instant message; something to draw you away from what is being presented. To make matters worse, you have probably never even seen the code before and maybe don’t even understand the design. How much can you really contribute, other than noticing the most obvious issues? The above graph shows the range of code reviews, from a formality perspective. Not that the process has to be this rigid, but I think it is important to discuss the stages and roles of an inspection:
This first one really drives me crazy, but unfortunately, this appears to be the way that most teams perform their “code reviews”. First, the presenter/reader sets up a phone line for all of the participants to dial into, even if they all sit together in the same area! Next, the presenter sets up a “net meeting” and walks the team through the code; adding comments or making small fixes along the way. Maybe I have too limited of an attention span, but I don’t really commit to this type of code review, nor do many others from my observations. Inevitably, someone comes by with a question, or you get an interesting email or instant message; something to draw you away from what is being presented. To make matters worse, you have probably never even seen the code before and maybe don’t even understand the design. How much can you really contribute, other than noticing the most obvious issues? The above graph shows the range of code reviews, from a formality perspective. Not that the process has to be this rigid, but I think it is important to discuss the stages and roles of an inspection: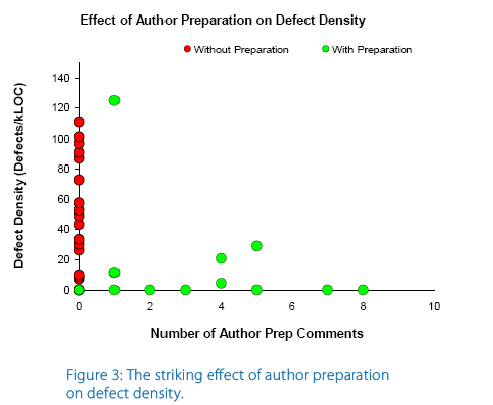 My second point is about preparation. I generally don’t think that most developers are very effective at “thinking on their feet”. It is really not about intelligence, but more about communication. Teams are typically very diverse, both technically and it the way they consume (process) information. It can be very difficult to present code at a level which will be effective for everyone to understand and process. In my opinion, no preparation is equivalent to
My second point is about preparation. I generally don’t think that most developers are very effective at “thinking on their feet”. It is really not about intelligence, but more about communication. Teams are typically very diverse, both technically and it the way they consume (process) information. It can be very difficult to present code at a level which will be effective for everyone to understand and process. In my opinion, no preparation is equivalent to 